Daten, Algorithmen und glückliche Bücherwürmer


Vanessa Kraiss und Samira Seckner studieren an der Hochschule der Medien Stuttgart Druck- und Medientechnologie. Im Rahmen eines Studienprojektes haben sie im Wintersemester 2020/21 ein Programm entwickelt, das dem Benutzer auf Basis von persönlichen Vorlieben Bücher empfiehlt. Beide lesen gerne, wollten sogar mal einen eigenen Bücherblog schreiben. Samira hatte sich zuvor in einer wissenschaftlichen Arbeit mit Datenbanken beschäftigt, und sah die Chance, ihr Wissen praktisch anzuwenden.

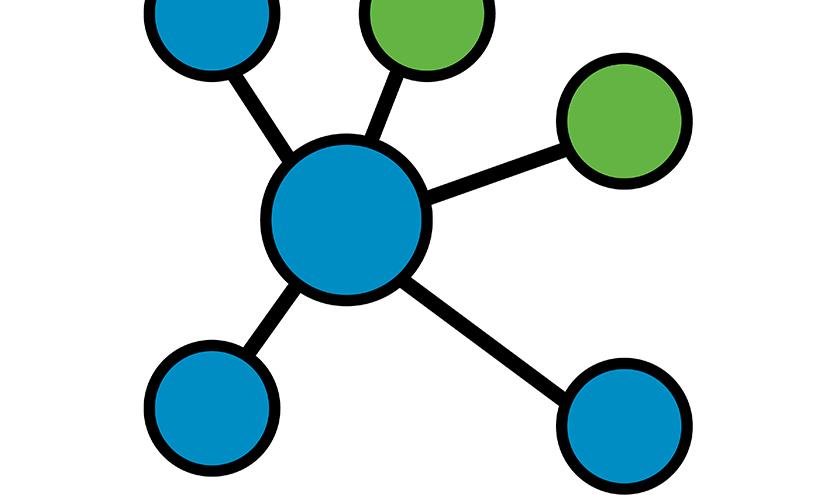
Zusammen haben die Studentinnen eine Buchempfehlungs-Engine ausgearbeitet, die auf einer Datenbank mit knapp 25.000 Datensätzen beruht. Darin sind einzelne Bücher zusammen mit Autor*in und den Genres gespeichert, die von dem Buch bedient werden. Das Besondere: Es handelt sich um eine sogenannte Graph-Datenbank. Die sichert nicht nur Daten, sondern kann sie auch vernetzen. So können komplexe Beziehungen zwischen einzelnen Informationen, sogenannten Entitys, gespeichert werden. Visualisiert erinnert die Datenbank an eine Mindmap – was sich im Logo des Projekts wiederfindet. Die Kreise stellen dabei die Entitys da. Pfeile symbolisieren die Beziehung der Entitys zueinander. Ausgewertet werden diese Daten von speziellen Algorithmen. Die durchsuchen und sortieren die Datenbank nach mathematischen Vorgaben, um am Ende zu einer konkreten Buchempfehlung zu kommen.
Wenn man ein gutes Buch gelesen hat, kann man sich so die Bücher ähnlicher Autor*innen oder ähnliche Titel aus demselben Genre anzeigen lassen. Außerdem kann man Buchtitel mit Sternen bewerten. So lernt das System die eigenen Vorlieben kennen und sucht dann nach Büchern, die anderen Nutzern mit ähnlichen Lesegewohnheiten gefallen haben.
Die personalisierten Vorschläge der Streamingdienste funktionieren nach dem gleichen Prinzip. Es gibt aber noch einige Hindernisse zu überwinden, bis die Anwendung wirklich nutzbar ist. Aktuell funktioniert sie nur für englischsprachige Fantasyromane. Für deutsche Literatur gibt es noch keine passenden, zugänglichen Datenbanken. Samira und Vanessa fehlt zum Weiterentwickeln die Zeit, sie sind ab dem nächsten Semester mit ihrer Bachelorarbeit beschäftigt. „Entweder es bleibt liegen, und es kümmert sich niemand darum – oder es wird von einem anderen Team weiterentwickelt“, erklärt Samira im Interview. Bis dahin bleibt die Engine Eigentum der Hochschule.
Über diesen Link gelangt ihr zur Buchempfehlungs-Engine auf der Media Night am 4. Februar. Und wir haben mit den beiden Programmiererinnen auch ein Interview geführt, das ihr hier findet.